画像生成AIと文章生成AIの比較および人間の知覚システムに対する仮説
2022年7月に画像生成AIの大きな動きがありました。米国企業のMidjourney, Inc.がMidjourneyを公開し、研究者でない一般人も画像生成AIを試すことができました。その後すぐ、英国のスタートアップのStability.AIがStableDiffusionを無料配布し、一気に画像生成のブームが来ました。画像生成AIは2015年のDiffusion Models*1をベースとしています。
一方、2022年12月にはAIを研究する非営利団体のOpenAIが文章生成AIのChatGPTを発表しました。ChatGPTのテスト版が一般公開され、またたく間にユーザー数は100万人を超えました。ChatGPTは対話のみならず文章の編集やプログラミング、Linuxシステムのエミュレート等を実行でき、その非常に汎用的な能力が話題となりました。ChatGPTはOpenAIが2018年に公開した大規模言語モデルGPT-1*2をベースにしています。さらにGPT-1は2017年に発表された、翻訳やテキスト要約等のタスクのためのモデルTransformer*3をベースにしています。
ところで、画像生成AIはDiffusion Modelsをベースとし、文章生成AIはTransformerのデコーダーをベースにしています。この違いはどこから生じるのでしょうか。また、人間の知覚システムと比較したとき、AIと異なる点は何でしょうか。本記事では画像生成AIと文章生成AIの比較をしながら、人間の知覚システムの考察へ接続を試みたいと思います。
モデルの構造の比較
簡単にそれぞれのモデルのおさらいにしましょう。

Diffusion Modelsは上図のような構造をしていました。Forwardプロセスは、タイムステップを進むにつれて微小なノイズをかけていくプロセスです。このプロセスはノイズをかけるだけなので、モデルの学習は行われません。Reverseプロセスはノイズ画像から元の画像を復元するプロセスです。学習時はノイズをかけた画像から元の画像を復元するように学習します。デプロイ時は完全なノイズから画像を生成します。

GPT-1、すなわちTransformerのデコーダーは上図のような構造をしていました。一番下に並ぶは入力する文章のそれぞれの単語です。添字は単語の順番を表します。タイムステップとも呼びます。BOSは特殊な単語で、文章生成のきっかけとなる文頭を表す記号の単語です。
は埋め込み器で変換された単語のベクトル表現です。上付きの添字は層を表します。
は特徴抽出器で変換された特徴ベクトルです。一番上に並ぶ
は予測した単語です。学習時は入力文章を1単語ずらしたものを出力文章となるように学習します。デプロイ時は続きを予測したい文章を入力し、続きの文章を生成します。
Diffusion Modelsを実装したことがある人は知っていますが、Diffusion Modelsの学習では完全なノイズ画像からの復元のみを行っているわけではありません。

上図はDiffusion Modelsの学習で使用するデータのポンチ絵です。Diffusion Modelsの学習では、ノイズの強さを表すタイムステップを様々に選び、様々なノイズ画像に対して元の画像を復元するように学習します。Diffusion Modelsを関数だと思うと、ノイズを予測する機能は
のように、ノイズ画像とタイムステップを入力します。Diffusion Modelsのニューラルネットワークはタイムステップ
に応じて除去するノイズのレベルを制御します。タイムステップごとにモデルがあるのではありません。
完全なノイズから画像を生成するプロセスでは、ノイズ画像から段々と大まかな画像が現れ、最後の方のステップで細かいディテールが追加されます。これを1つのニューラルネットワークで行います。除去するノイズのレベルはタイムステップで制御されます。このタイムステップによる制御によって、モデルは低周波(画像の大規模な構造)から高周波(画像のディテール)へと効果的に画像を生成します。
さらに発展的な話をすると、Diffusion Modelsの拡散過程は階層型のVariational Autoencoder (VAE) *4 を具体的に実現したものと考えることができます*5。Diffusion ModelsはForwardプロセスが学習パラメータを持たなかったり、潜在変数(ノイズ画像)が標準ガウス分布に従うため情報を持たなかったりとAutoencoderと異なる点もありますが、潜在変数(ノイズ画像)から画像を生成する点ではAutoencoderと共通しています。
余談ですが、Diffusion ModelsはDenoising Autoencoder *6にも類似しています。また、Diffusion ModelsのニューラルネットワークにはU-Net*7が使用されており、これ自体が残差接続を持つAutoencoder*8とみなせます。Diffusion Modelsは様々な点でAutoencoderと関係があるモデルとなっています。
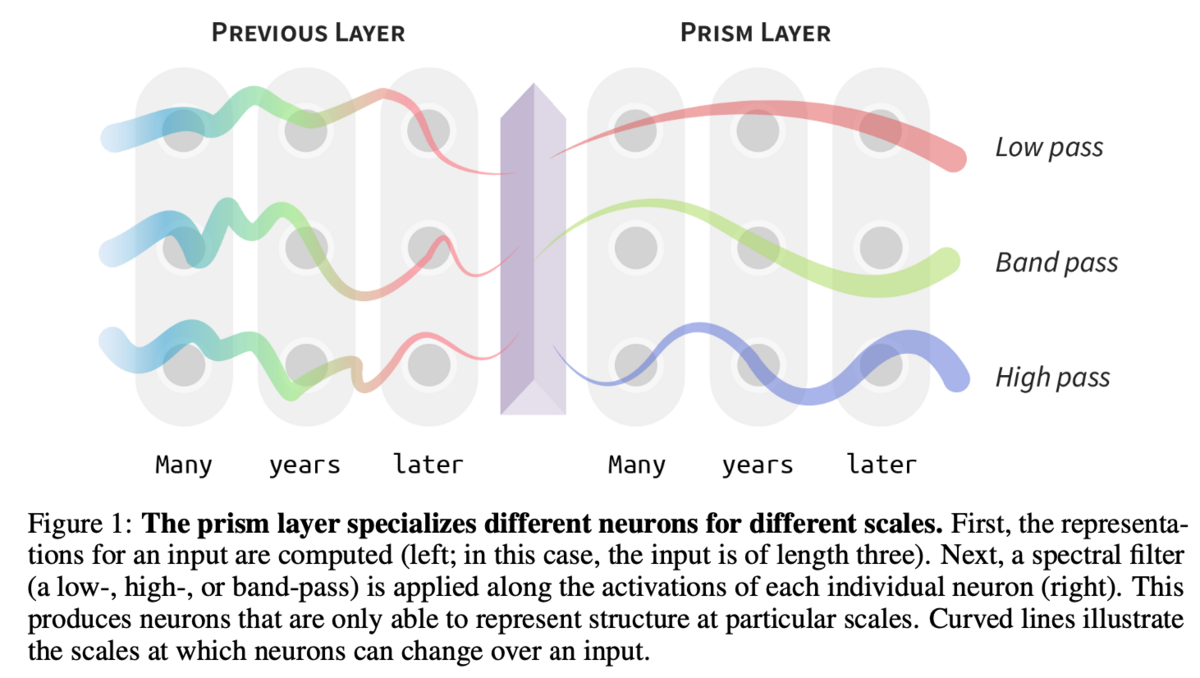
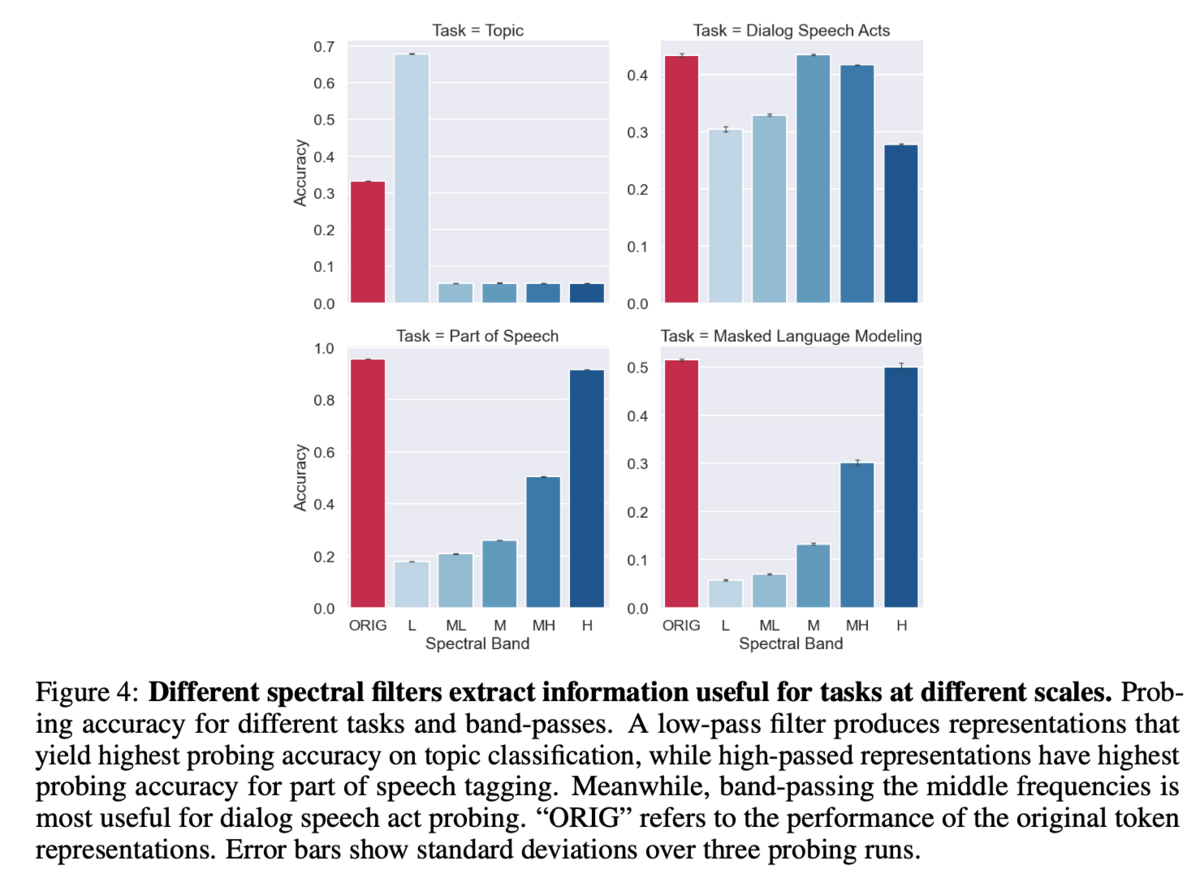
自然言語における「低周波」と「高周波」はなんでしょうか。「低周波」は文章の大規模な構造、すなわち文脈や意味を指し、「高周波」は具体的な単語を指すと考えられます*9。上図は自然言語モデルの時系列特徴量に対して、ハイパスフィルタとローパスフィルタをかけ、どの成分がどのような予測に寄与しているかを調べたものです。ローパスフィルタされた特徴量は文章のトピックを当てるのに長けており、ハイパスフィルタされた特徴量は品詞タグ付け等に長けています。
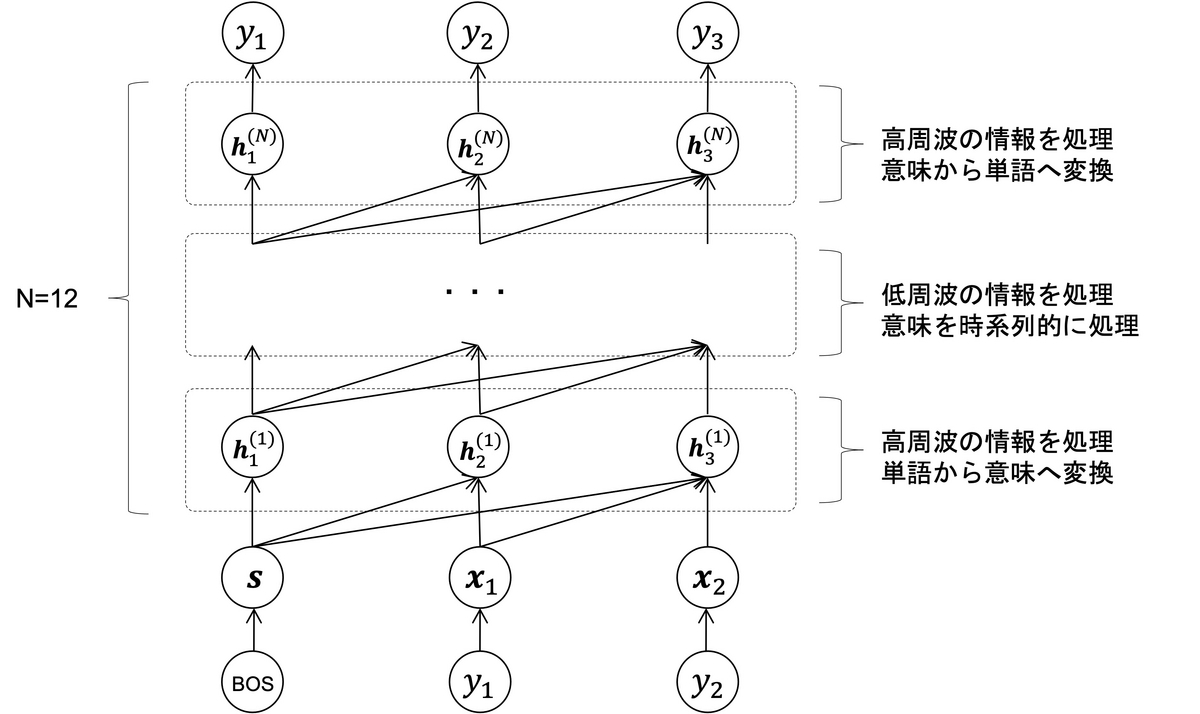
自然言語を処理するGPT-1には、「低周波」と「高周波」を制御するようなパラメータがありません。したがって、GPT-1のニューラルネットワークは層ごとに「低周波」と「高周波」の情報を処理するように役割分担していると筆者は考えます。これはまるでAutoencoderのようです。
元々自然言語の生成モデルはAutoencoderの要素を取り入れるためにエンコーダーとデコーダーに分けることでボトルネック*10を導入しました。それがなんやかんやあって、GPT-1ではTransformerにあったエンコーダーを取り除き、結局デコーダーのみを使用しています。Diffusion Modelsもボトルネックが不要であったため、生成モデルはデータとマシンリソースがあればボトルネックが無いほうが良いのかもしれません。
Diffusion Modelsによる文章生成
Diffusion Modelsで自然言語を生成できるでしょうか。私たちがパラグラフを書くとき、一般的にはまず核となるコンセプトが決まり、正確な表現や言い回しが決まるのはその後になります。これはDiffusion Modelsが大規模な構造からディテールを構成していくプロセスに向いているように思えます。
文章は離散的なトークン(単語のこと)の列であり、そのままガウシアンノイズをかけることができません。離散的なデータに対するノイズの検討も行われていますが、連続変数に対するサンプリング手法が使い回せない等の制約を受けます。一方、単語を埋め込んだベクトルは連続値になるので、ガウシアンノイズをかけることができます。Diffusion-LM*11では、ガウスベクトルを反復的に単語ベクトルにノイズ除去し、中間潜在変数の列を生成します。中間変数の連続的、階層的な性質により、複雑で制御可能な生成タスクを実行することができています。LD4LG*12では、学習済みのBART*13を単語の埋め込みに利用しています。BARTはBERT*14をseq2seqの形にしたものです。
また類似する手法に音声生成モデルのRiffusion*15があります。これはスペクトログラムをDiffusion Modelsで生成し、音声に逆変換することで、音声を生成します。
しかし、Diffusion Modelsによる言語生成モデルは問題点もあると指摘されています*16。StableDiffusionは23億枚の画像で学習を行っています。一方、ChatGPTは570GBのテキストデータで学習を行っています。Diffusion Modelsは一つのデータに対して複数レベルのノイズをかけたもので学習を行います。これはデータの量よりも学習量が大きくなることを意味しており、画像よりも量が多いテキストでは学習時間が多くなります。さらにChatGPTの推論ステップはたかだかトークン数程度ですが、Diffusion Modelsの推論に必要なステップは1000程度のタイムステップになります。このステップの計算量が効率的かも問題になります。
さて、ここまでは連続値を持つベクトルの議論をしていましたが、自然言語を生成するChatGPTの方には最終層に特別な層がありますね。そうです、分類器があるのです。言語は離散的なトークンの列であるため、低周波な情報を高周波な情報に変換する必要があります*17。分類機では、特徴ベクトルがどのトークンに対応するかの分布を計算します。決定論的なモデルではこの分布からargmax(最大点集合)を取得します。確率的なモデルでは、分布に応じて確率的にサンプリングします。
低周波情報から高周波情報への変換は、例えばOCRのように文字が書いてある画像から文字を読み取るといったことも当てはまります。例えばDiffusion Modelsで文章画像を生成して、OCRモデルで文字を読取るといったことも考えられます。
人間の知覚システムに対する仮説
人間の記憶は低周波情報を重視しているのではないしょうか。私的な経験ですが、大雑把な景色を覚えてることはあっても、ディテールまで覚えていないことが多いです。歴史的出来事も、大体こういう感じの事件があったということは覚えていても、教科書の文章を一言一句覚えてはいません。
記憶術*18の「イメージ記憶」「ストーリー記憶」「場所法」はどれも高周波な情報を低周波な情報に結びつけるメソッドだと思います。筆者は教科書を暗記するとき、単に内容を覚えるのではなく、教科書の最初の方のページで、挿絵の隣のこの辺りにXXが書いてあった、のように低周波の情報と結びつけて覚えているような気がします*19。
こう考えると、人間の知覚システムは低周波情報を重視しているというよりは、主に低周波情報を処理しつつ高周波への変換をアドホックに学習しているという感じでしょうか。
人間は高周波情報の出力も苦手ではないでしょうか。ブログにこういう感じの内容を書きたいと思っても、なかなか言葉が出てこないことが多いです。中学数学で最初に躓いたのは証明問題で、直感的に合同な三角形を文章で説明することはとても難しかった記憶があります。
レタリングは文字を絵として描いているので、低周波情報と高周波情報を結びつける重要な役割を果たしているのかもしれません。普段からPCを使用するようになってタイピングになってから、漢字を書けなくなった気がします。
また、人間はargmax(最大点集合)の処理が苦手ではないでしょうか。筆者は文章作成や穴埋め問題で言葉を選ぶとき、誤った用法の単語を選ぶことがあります。これは、意味が類似した単語の出力確率がほとんど同じであった場合に、argmaxをうまく処理できず迷ってしまうからではないでしょうか。
伝達エラーと解釈の余地
言語によるコミュニケーションはエラーが発生することが多々あります。それは、言葉の曖昧さや、話者と聞き手の理解のズレが原因となります。連続的なベクトルを離散トークンに変換するときに情報が欠落することも、このエラーの一因です。意味や概念のベクトルをトークンに変換することで、元々持っていた意味やニュアンスが失われることがあります。
そもそも、異なる人が同じ単語を思い浮かべたとき、その意味を表すベクトルは同じものになるのでしょうか。単語の意味や印象は言語の習得や個人の経験に依存するので、異なるものになるように思えます。ところが、自然言語処理の研究においては、異なる言語の埋め込みベクトル集合は(直交変換の自由度を除いて)よく一致することが知られています*20。これが異なる人間の言語間にも当てはまるのであれば、異なる人の脳の中の単語ベクトルもほとんど一致すると期待できるのではないでしょうか。
とまれ、人間のコミュニケーションで高周波な言語を使用する以上、微小な伝達エラーが発生します。しかし、それを悪いことと捉えるのではなく、むしろポジティブに捉えることによって、文章の解釈の余地が生まれるという見方もできます。
小説を読んだときに思い浮かべるイメージが違って多様性が生まれたり、過去の哲学者の思想を再解釈して現代に活かしたり、良いか悪いか置いておいて法律を解釈変更してやり過ごしたり、そうやって社会が動いている側面はあると思います。
ChatGPTが普段使いされるようになれば、情報を送る方もChatGPTを使用して情報を生成し、受け取る方もChatGPTを使って要約するかもしれません。しかし、情報を言語に変換してやり取りする以上、エラーは発生すると思われます。もうChatGPTが全部仲介してくれと思うわけです。
近い将来、ブレイン・マシン・インターフェースのようなものが登場し、意味や概念を直接伝えることができるような世界が来るかもしれません。もし、脳と脳を繋げて情報伝達にエラーが起きないようになった場合、それはもはや2つの脳ではなく、1つの脳になったと考えるべきではないでしょうか。ニューラルネットワークも2つのネットワークを1つにつなげた場合、1つのネットワークとして扱います*21。脳が1つになってしまうと、エラーや摩擦が生じないため、知能が発達しないのではないでしょうか。知能の発達を目指さない動物は、本能を満たすことを目的とする最適化マシーンになってしまうのではないでしょうか。
大規模言語モデルを1社が独占して1つのAIを作るという行為は、万能な1つの脳を作るということであり、それを使用する人間を1つの脳に接続するということになります。これによって知性の多様性や創造性が失われ、人間はAIに従う最適化マシーンとして生きることになるのかもしれません。それは、結局、AIは人間の拡張システムではなく、人類補完計画*22のためのアンチATフィールドなのかもしれないという考えに至ります。
まとめ
これからの技術開発において、私たちはAIの役割とその限界を理解し、適切なバランスを見つけることが重要です。AIと人間が共に協力し、互いの長所を活かすことが求められます。また、異なる人間やAIが持つ多様な知識やアプローチを組み合わせることで、新たな発見や洞察が得られるでしょう。独占的な状況を避け、オープンで競争的な環境を維持することによって、技術や知性の発展に大きく貢献できます。
私たちの目指すべきは、人類補完計画のためのアンチATフィールドではなく、AIと人間が共存し、互いに学び合いながら発展する未来です。
その他参考図書
*1:Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N. & Ganguli, S.. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. Proceedings of the 32nd International Conference on Machine Learning, in Proceedings of Machine Learning Research 37:2256-2265 Available from https://proceedings.mlr.press/v37/sohl-dickstein15.html.
*2:Radford, Alec and Karthik Narasimhan. “Improving Language Understanding by Generative Pre-Training.” (2018).
*3:Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, 2017.
*4:Pinheiro Cinelli, Lucas; et al. (2021). "Variational Autoencoder". Variational Methods for Machine Learning with Applications to Deep Networks. Springer. pp. 111–149.
*5:Calvin Luo, "Understanding Diffusion Models: A Unified Perspective," arXiv: 2208:11970.
*6:Pascal Vincent, Hugo Larochelle, Yoshua Bengio and Pierre-Antoine Manzagol. Extracting and Composing Robust Features with Denoising Autoencoders. Proc. of ICML, 2008.
*7:Olaf Ronneberger, Philipp Fischer, Thomas Brox, "U-Net: Convolutional Networks for Biomedical Image Segmentation," Medical Image Computing and Computer-Assisted Intervention (MICCAI), Springer, LNCS, Vol.9351: 234--241, 2015, available at arXiv:1505.04597 [cs.CV]
*8:Geoffrey E. Hinton; R. R. Salakhutdinov (2006-07-28). “Reducing the Dimensionality of Data with Neural Networks”. Science 313 (5786): 504-507.
*9:Alex Tamkin, Dan Jurafsky, and Noah Goodman. 2020. Language through a prism: a spectral approach for multiscale language representations. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS'20). Curran Associates Inc., Red Hook, NY, USA, Article 461, 5492–5504.
*10:What Are “Bottlenecks” in Neural Networks? | Baeldung on Computer Science
*11:X. L. Li, J. Thickstun, I. Gulrajani, P. Liang, and T. B. Hashimoto, "Diffusion-lm improves controllable text generation," arXiv:2205.14217.
*12:Justin Lovelace, Varsha Kishore, Chao Wan, Eliot Shekhtman, Kilian Weinberger, "Latent Diffusion for Language Generation," arXiv:2212.09462.
*13:Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
*14:Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ArXiv, abs/1810.04805.
*15:Forsgren, Seth and Martiros, Hayk, "Riffusion - Stable diffusion for real-time music generation," 2022, https://riffusion.com/about
*16:Dieleman Sander, "Diffusion language models," 2023, https://sander.ai/2023/01/09/diffusion-language.html, (閲覧日2023/4/15).
*17:ちなみにDiffusion-LMでは連続ベクトルからトークンへの変換は、トークンの埋め込みベクトルとのL2(またはコサイン)類似度でargmax(最大点集合)を取得しています。LD4LGではBARTのデコーダーに分類器が内蔵されています。
*18:記憶術3選|記憶力世界一の使う3種類のテクニック | 記憶の学校|実生活で役立つ記憶術が身につく記憶スクール
*19:紙の本の重要性がここにある気がします。
*20:Xing, C., Wang, D., Liu, C., & Lin, Y. (2015). Normalized Word Embedding and Orthogonal Transform for Bilingual Word Translation. North American Chapter of the Association for Computational Linguistics.
*21:片方のネットワークを学習するとき、もう片方のネットワークをフリーズすれば2つのネットワークとして扱えそうですが、生体脳に同じことができるでしょうか。