概要
マーケティングにはいくつかのフレームワークがありますが、それぞれのフレームワークを連携させる方法について疑問に思う点がありました。疑問点とその解決法について書きたいと思います。
背景
最近、社内のマーケティング研修に参加しました。下記の図のようにフレームワークを連携させて分析を進めていく手法を学んだのですが、連携する際に不明瞭な点があり、うまく使いこなせませんでした。使い方について講師に質問しても、「マーケティングは理論だけじゃなくて情熱も必要だから!」という非論理的な回答をされてしまいました。
そこで、フレームワークの連携について改めて自分で整理し、フレームワーク間の連携と、ちょっとしたコツについてまとめました。個々のフレームワークの詳細は割愛します。
リコーさんのWebサイトに分かりやすい図がありましたので、こちらの図に沿ってまとめたいと思います。
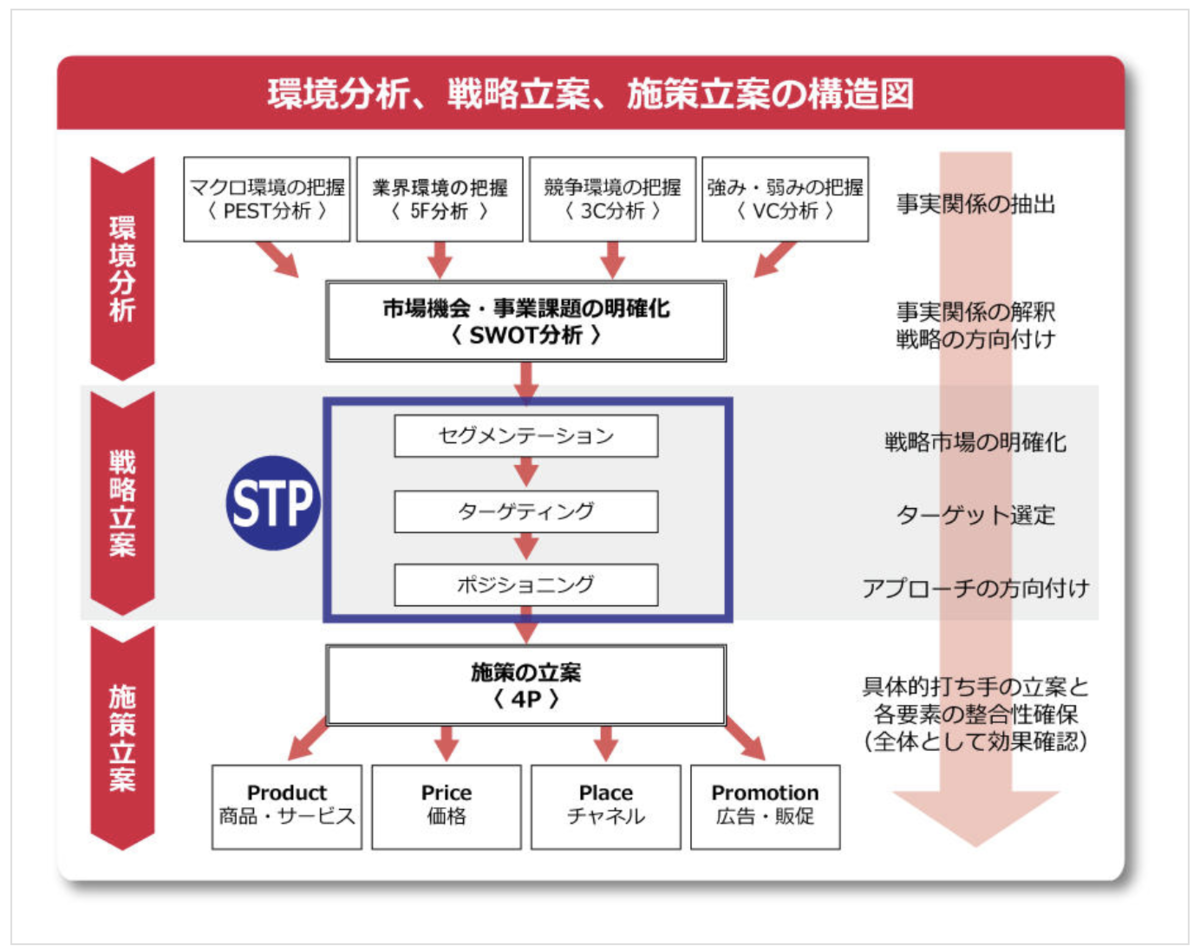
フレームワークの流れ
研修ではPEST → 5F → 3C → SWOT/クロスSWOT → STP → 4Pの順で分析を行いました。PEST/5F/3Cで事実を確認し、SWOTでそれらの分析をまとめました。その後、STPでターゲットを決め、4Pでプロダクトを考えました。一つ一つの手法についてはよくわかったのですが、これらを連携させるのが難しかったので、連携させるときのポイントを整理していきたいと思います。
PEST
PESTではマクロ環境分析を行います。自社のプロダクトの市場に影響を与えるマクロな要因を政治(法規制や政治的動き)/経済/社会(人口動態や習慣)/技術の観点で整理します。
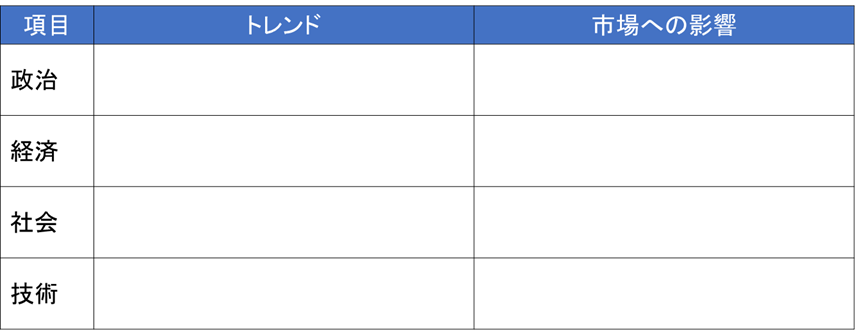
「トレンド」欄にはマクロ環境の客観的事実を記載します。それぞれの事実が市場に与える影響についての評価を「市場に与える影響」に記載します。
- このとき、影響がプラスなのかマイナスなのか切り分けます。切り分けにくいと感じたら、その事実の抽象度が高い可能性があるので、事実をさらに細かい要素に分解します。
- 市場に与える影響を考えにくい場合は、その市場の売り上げ構造について振り返ってみるとよいです。おおむね(価格)×(個数)×(満足度)の観点で考えればよいと思います。価格であれば、材料の原価、人件費、配送費、ブランド、コモデティ化などが考えられます。個数であれば需要、シェア、生産力、販売チャネル、購入サイクル、代替品の登場、法規制などが考えられます。満足度については品質や納期などがあります。
難点は、マクロ要因が市場に与える影響の確からしさがわからないということです。例えば、「政治状況が良いから市場が拡大する」と思っても、因果関係を証明するのはまず無理です。したがって、PEST分析は大きな流れを見て、これから検討する戦略の筋が悪いかどうかを判断するための制限のようにとらえると良いと思います。日本はどんどん人口が減っていくのにたくさん売ってなんぼの商品は筋が悪い、といった具合です。
5F
5Fは業界構造の現状を分析する手法です。既存企業の状況、川上川下の交渉力の強さ、参入障壁や代替製品について整理し、収益性を判断します。ここで、収益性とは製品の粗利です。5Fは事実ベースで調査が可能なのでやりやすいと思います。
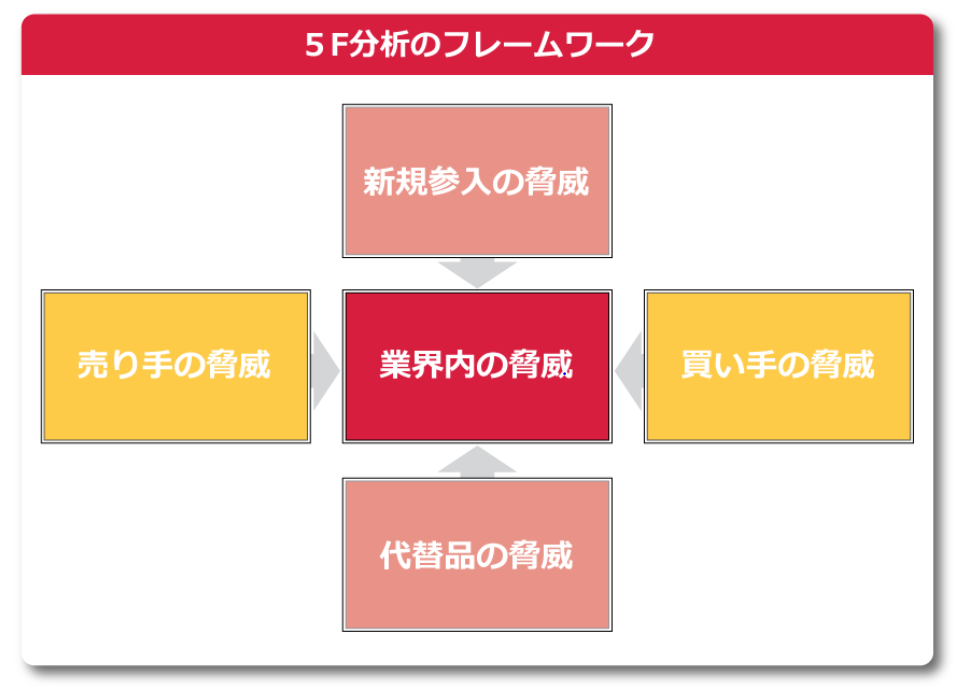
難点は、それぞれの状況が自社にとって有利か不利か判断するのに主観が入るという点です。例えば、一般に自社製品の部品製造業者が少ない場合は、部品製造業者の交渉力が強く不利と判断します。ですが何社くらいから少ないといえるでしょうか?この辺の判断は業界に関係する企業について深い知識が必要なので、経験値によっては判断が異なる場合があります。
3C
3Cは、顧客、競合、自社の三つを分析します。どんな顧客がいて、どんなニーズを持っているのか、競合はニーズに対してどのように対応しているか、それを受けて自社はどのように強みを活かす(差別化する)か、弱みは何か、を整理し、 重要成功要因(KSF)を見つけ出します。
- 最も重要なのは顧客の分析で、ここが全ての土台となります。セグメンテーションは後程行うので、この段階では業界の顧客全体を想定し、様々なニーズ、市場規模とその変化を整理します。
- ニーズに対して競合企業がどのように対応しているか、具体的には価格/種類/品質/ブランディングなどリソースと仕組みを調査します。このとき、競合の動向を具体的に調査するのですが、その内容を抽象化して競合がどのような「価値」を訴求しているのかに焦点を置きます。なぜかというと、具体論に入りすぎると、自社について考える際に具体論になってしまい、事実確認フェーズなのに解決法に思考が向いてしまうからです。
- 顧客と競合の状況が整理できたら、それらを比較参考にして自社はどのように対応できているか整理します。そして他社との差別化ができそうな方向性を抽出し、KSFとします。ここで、検討するのはあくまで方向性で、具体的な方法は考えません。
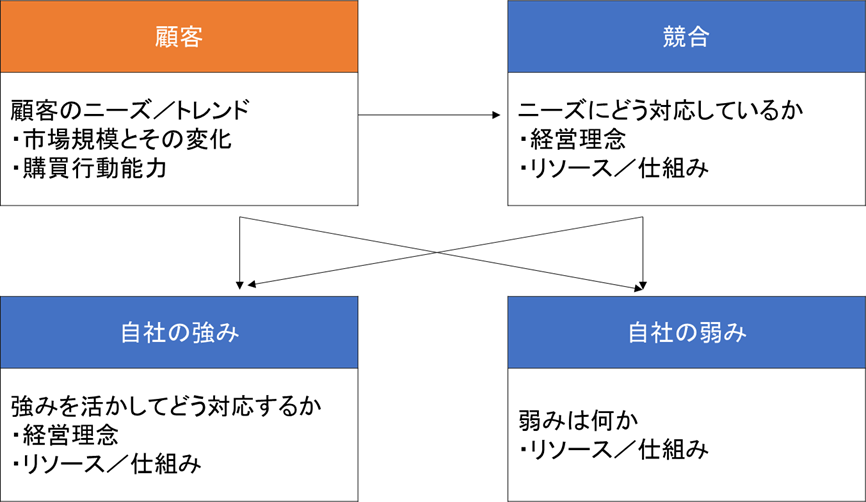
以上、3つの手法で次のことを行いました。
- PEST: 市場に影響を与えるマクロ要因を整理する
- 5F: 業界の収益性を整理する
- 3C: 重要成功要因(KSF)を見つけ出す
SWOT(クロスSWOT)
SWOTでは内部環境の「強み」と「弱み」、外部環境による「機会」と「脅威」を整理します。内部環境とは自分たちで制御可能なもの、外部環境とは自分たちで制御できないものを指します。 PEST/5F/3Cをすでに行っているので、これらをマッピングすることですぐにSWOTを作成できます。
- 強み: 3Cの自社の強み(差別化できる要素)
- 弱み: 3Cの自社の弱み(競合より劣る要素)
- 機会/脅威: PESTおよび5Fから導かれる業界の動向や市場規およびその変化、3Cおよび5Fから導かれる顧客のトレンド/ニーズや業界構造の問題
作成したSWOTからクロスSWOTを行います。SWとOTを掛け合わせて自社がとるべき方向性を整理します。

- 要素を掛け合わせると、ついつい解決策まで考えがおよびますが、具体論は考えず、方向性にとどめます。着目する業界の動向と活かすべき強み、克服すべき弱みを羅列するくらいでいいと思います。
- いくつかの掛け合わせを検討した後、実際に実施すべき方向性をいくつか採用します
STP
SWOTで採用した方向性をもとに、セグメンテーション/ターゲッティング/ポジショニングを進めます。 SWOTの方向性を決める際に着目した顧客のニーズがあると思いますので、そのニーズを持つ顧客の属性を整理します。整理する観点は引用します。
- 「地理的変数」・・・国や地域、都市の規模、発展度、人口、気候、文化・生活習慣、宗教など
- 「人口統計的変数」・・・年齢、性別、職業、所得や学歴、家族構成など
- 「心理的変数」・・・価値観、趣味嗜好、ライフスタイルなど
- 「行動変数」・・・購買状況や購買パターン、使用頻度といった製品に対する買い手の知識・態度・反応など
職業/性別/性格...などセグメンテーションする属性を決めたら、そのうち現実に存在する組み合わせのパターンを考えます。例えばバリキャリ、女性、アウトドア志向.../事務職、女性、サブカル系...のような感じです。ある程度パターンが出来たら、実際にその人物が実在しているかのような、リアリティが出るレベルまで緻密化します。このユーザー像のことをペルソナといいます。例えば、コンサル業、女性、30歳、趣味はサーフィンとスノボ、年下彼氏、港区在住、タワマン住み、車はアウディ、食事は常に外食...のような感じです。
- ペルソナを考える際、「平均的な人」を考えてはいけません。メーカー勤め、男性、40歳、趣味は映画...といった具合の平凡な設定はイメージしやすいものの、特化する部分がないので、商品戦略を考える際に商品も特徴的なものになりにくくなってしまいます。イノベーター理論によると、最初に商品が売れるのはイノベーターやアーリーアダプターです。これらの人々に商品が浸透すると、マジョリティが商品の価値を理解して買ってくれるようになります。したがって最初に商品を届けるイノベーターやアーリーアダプターはマジョリティにとってのモデルケースとなるような「イカした」人物であることが求められます。取り組みやすいのは、世間ですでに浸透しているレッテル(ITオタクや草食男子など)を利用するか、有名人で例えることです。
- また、本質的には平均的な人間なんていないことに注意しましょう。各人それぞれ独特のこだわりを持っているものです。しかし、いざペルソナを作ろうとすると平均化してしまいがちなので、注意しましょう。
- ペルソナが出来たら、ニーズを緻密化します。リアリティに基づいた、より詳細なニーズの深堀を行います。そして、各ペルソナにとって商品購入の決め手が何かを抽出します。この決め手を重要購買決定要因(KBF)といいます。このとき、SWOTで想定したニーズに合わないペルソナはターゲティング候補から外します。
次にターゲティングを行います。それぞれのペルソナと似た集団をセグメントと考え、そのセグメントの市場の規模、競合の参入状況、自社の強みを活かせるか評価します。
総合的に判断して、ターゲットとするセグメントを確定します。
最後にポジショニングを行います。ターゲティングで決めたセグメントのペルソナのKBFを軸にとって、自社と競合をマッピングして差別化できているか確認します。
- 差別化できていない場合は3Cの自社の強み分析が足りない可能性があります。もう一度3Cに戻って検討し直します。
- 自社や競合が斜め一直線に並ぶ場合は、KBFの軸どうしに相関がある可能性があります。例えば、価格と機能などです。高機能ほど高価格になるのは当たり前なので、これだと役に立つ分析とは言えません。KBFの軸に取るのは、○○が高いor低いではなく、例えば高級さ⇔手軽さのように、軸の両端に価値があるようにしたほうが良いです。対立概念をしっかり考えましょう。
- KBFはあくまでも「価値」です。具体的な機能があるorない、とならないようにします。
4P
ここまででニーズとターゲットセグメントが決定しました。これを受けて、ニーズを満たす商品を考えます。
- KBFを支える機能やデザインを持つプロダクト、付随機能/サービスを提供する。
- 利益が出るプライスの設定をする。規模と価格のバランスをとる。
- ターゲットとする顧客まで届くための販売プレイスを用意する。
- イノベーター/アーリーアダプター/マジョリティで分けたプロモーションを行う。
この4Pを考える上でも、顧客のニーズが中心だということに気を付けます。なるべく製品開発側の都合を排除し、あくまで顧客が必要な機能か、需要がある価格か、販売プレイスを利用できるか、どれくらい関心があるか、で判断します。
以上でマーケティングによるプロダクト企画ができました。