StableDiffusionやChatGPTが現れたが、これらAIの出現はWeb3.0の到来ではないだろうか。
Web3.0とWeb3は別物
Web3.0はティム・バーナーズ・リーが1998年頃から提唱していたセマンティックWebのことを指す。
セマンティックWebとは、Webページに記述された内容について、それが何を意味するかを表す「情報についての情報」(メタデータ)を一定の規則に従って付加し、コンピュータシステムによる自律的な情報の収集や加工を可能にする構想。 IT用語辞典 e-Words, "セマンティックWeb 【Semantic Web】," URL
一方でWeb3はEthereumの共同創設者の一人ギャビン・ウッドが提唱した概念である。一言で説明するなら、検索でトップに出てきたSMBC日興証券の用語集が参考になる。
Web3とは、次世代のインターネットを表す言葉で、主にブロックチェーン技術によって実現される分散型ネットワークを指します。 SMBC日興証券, "Web3 (ウェブスリー)," URL
実際はWeb3が指すものは漠然としており、Wikipediaの説明が分かりやすい。
Web3の具体的な構想は人によって異なり、ブルームバーグはこの用語について「漠然としている」と評している。しかしながら、基本的には分散化(英: decentralization、非中央集権・脱中央集権)というアイデアに準拠しており、さまざまな暗号通貨や、非代替性トークン(英: non-fungible token、NFT)などのブロックチェーン技術が組み込まれていることが多い "Web3," Wikipedia, URL.
ただ、ギャビン・ウッドのブログからは、彼が最も重要視していることはゼロトラストではないかと筆者は思う。
Web 3.0, or as might be termed the "post-Snowden" web, is a reimagination of the sorts of things that we already use the Web for, but with a fundamentally different model for the interactions between parties. Information that we assume to be public, we publish. Information that we assume to be agreed, we place on a consensus-ledger. Information that we assume to be private, we keep secret and never reveal. Communication always takes place over encrypted channels and only with pseudonymous identities as endpoints; never with anything traceable (such as IP addresses). In short, we engineer the system to mathematically enforce our prior assumptions, since no government or organisation can reasonably be trusted. Gavin Wood, "ĐApps: What Web 3.0 Looks Like," URL.
Web3.0を体現した生成AI
Web3.0の当時の熱量はもう分からないが、構想としてセマンティックWebがあったようだ。システムが自律的にWebの情報を収集・解釈し、意味的な検索を可能にしたり、システム間でデータ連携したりすることを目標としていたらしい。
ChatGPT等の大規模言語モデルやStableDiffusion等の画像生成モデルを組み合わせた情報検索システム(もはや生成だが)はWeb3.0を体現しているように思える。「Webは1つのデータベースになる」、という構想はWebサイトにメタデータを付けるのではなく、Webクローラーによる情報収集とAIによる学習によって実現した。
今のところ、セマンティックWebが想定していたシステムの相互連携はWeb APIによって行われている。今やAIもWeb APIで提供されている。Web APIの成果はWeb2.0の範疇らしいので、Web3.0のシステム連携は互いのシステムのデータをクロールし合うシステムになるのかもしれない。
そう考えると、検索エンジンと生成AIは対立構造にあるのではなく、セマンティックWebという一つの括りであると考えられる。これらの技術を牽引するビッグテックが引き続き覇権を握るのかもしれない。
次に来るのはWeb4.0?
順当に考えると、次に来るのはWeb4.0ではないだろうか。インターネットで検索するとWeb4.0という用語も氾濫していて何が何やらだが、2000年代の予測資料(もはやブログくらいしか出てこないが)をいくつか見ると、人工知能(HAL 9000のようなパーソナルインテリジェント)の構想は共通しているようだ。
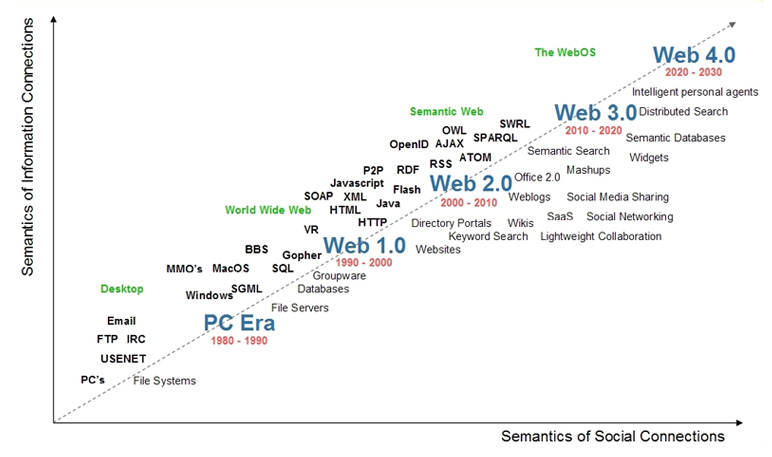
人間とWebを仲介するエージェントの実現には、現実世界の情報化と自律的AIが不可欠だろう。AGIの研究に向けた議論も動き出しているようだ。現実世界のデータ収集はIoTが担っていたが、収集したデータの統合やスマートグラス等を活用した人間の感覚器のデータ化はあまり進んでいないように思う。Web4.0の実現にはハードウェアの進化が必要だとすると、まだ未来のことなのかもしれない。
Web3はどうなるのか
ではWeb3はどうなるのか。非中央集権化というテーマは非常に大きな課題だ。ビッグテックのプラットフォームが仕様を1つ変えるたびに慌てふためく世界というのは健全ではない。
かと言ってブロックチェーンで出来ることには限界があると筆者は思う。トークンエコノミーを利用した福祉領域のルールデザインおよびセキュリティ領域等でのブロックチェーン活用の可能性は残るが、注目されているのは投機システムばかりで、これは暗号資産同様規制の対象になるだろう。
私達が考えるべくは、私達のシステムをいかにビッグテックから解放するかということである。
例えばシステムの受益者が集まって、システムの開発運用を共同運営することが考えられる。具体的には、Uber Eatsがシステムを停止しても平気なように、ドライバー達で共同で「Open Uber Eats」なるものを構築するといった具合である。このような、ある種のパブリックなシステム運用を実現できるかが問題になると考えられる。
Web3関連技術としてメタバースにも触れておく(全く関係ないと怒られるかもしれないが)。メタバース技術をWeb3.0にアラインするなら、現実のシミュレーターとして活用するのが良いのではないか。アラン・ケイの「ユーザー・イリュージョン*1」と類するユーザーインターフェースとしての可能性を追求したほうが筋が良さそうに思える。現実との接続を踏まえるとVRよりもARのほうが有望ではないだろうか。インターフェースはまさに3D粘土を手でこねるといった、もっと「柔らかい」インターフェースが必要になるだろう。バーチャルろくろはとても良いアイデアではないだろうか。
まとめ
Web3.0のセマンティックWebとその周辺技術が現実になってきた*2。今後出てくるであろうパーソナルインテリジェントも楽しみである。ロックマンエグゼ*3みたいな世界が来るのかもしれない。一方、ロックマンエグゼのストーリーと同じく、ハードウェアの進化が相対的に遅れると、Webと現実の接続はまだまだ先のことになるかもしれない。
Web3という言葉はよく分からないことになっている*4が、スマートコントラクトによる非中央集権化やリソース分担による取引コストの低減は良い傾向だと思う。一方で、NFTのような、全てを投機対象にしようという動きには筆者は懐疑的だ。また、ソフトウェア的なコントラクトの先にある、ハードウェア的な分散、そしてプラットフォームに支配されないようにどうやって受益者負担のシステムを作れるのかといった点が課題になると考える。
*2:筆者は当時のセマンティックWebの空気感が分からないので、当時に詳しい人はぜひ記事を書いて頂きたい。